心血来潮,昨天看见群里讨论一段图片转pdf的代码,直接拿过来发现不能用,原来是因为代码中传的文件对象不对,源码中说传递的是一个文件路径或一个文件对象。他传的是一个文件名,很是尴尬。
想了想,主要原因还是因为很多人不看源码,看了源码经常因为大段的注释英文看不懂,很是尴尬。
然后想了想,是否可以写一个翻译功能对源码进行翻译。功能实现,代码如下:
翻译中文的代码(使用有道翻译= =):
1 def fanyi_youdao(self,content): 2 url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' 3 data = {} 4 data['i'] = content 5 data['to'] = 'AUTO' 6 data['smartresult'] = 'dict' 7 data['client'] = 'fanyideskweb' 8 data['salt'] = '1517200217152' 9 data['sign'] = 'fc8a26607798294e102f7b4e60cc2686'10 data['doctype'] = 'json'11 data['version'] = '2.1'12 data['keyfrom'] = 'fanyi.web'13 data['action'] = 'FY_BY_CLICKBUTTION'14 data['typoResult'] = 'true'15 data = urllib.parse.urlencode(data).encode('utf-8')16 req = urllib.request.Request(url, data)17 req.add_header('User-Agent',18 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36')19 response = urllib.request.urlopen(req)20 html = response.read().decode('utf-8')21 22 target = json.loads(html)23 sumString = ''24 for i in target['translateResult']:25 for j in i:26 if(j['tgt']!=None):27 sumString+=j['tgt']+'\n'28 return sumString 最后有个小坑,经过json.loads转换后需要查看一下返回过来的值,因为target中翻译内容返回过来的list或dict不同,需要根据实际情况改变,其他的都是request的简单应用。
下面是替换翻译并复制出一个文件:
1 def del_zs(self): 2 with open(r"G:\re.py", "r") as file: 3 file_read = file.read() 4 en_content = re.findall('""".*?"""', file_read, re.S) 5 new_file_read = file_read 6 for i in en_content: 7 with open(r"G:\re_cn1.py","w+",encoding='UTF-8') as new_file: 8 new_file_read = new_file_read.replace(i, '"""\n' + self.fanyi_youdao(i.replace('\n', '')).strip().strip("“”") + '\n"""') 9 new_file.write(new_file_read)10 return en_content 这里是用到了python3中的re模块,思路就是使用正则匹配被"""夹着的内容(也就是注释),然后翻译内容(因为re匹配过来的内容是一个list所以就直接用for循环这个list)然后利用strip对中文翻译过来的引号进行删除,再加上英文的三引号。然后将翻译过来的内容利用list进行逐个replace,就可以实现了。
优化:
使用后发现有道翻译是真的不好用啊,经过百度发现竟然还有google翻译的第三方库,直接translate就可以了,补上代码:
注意要----------pip install googletrans
1 def fanyi_google(self,content):2 # 使用方法3 translator = Translator(service_urls=['translate.google.cn'])4 source = content5 text = translator.translate(source, src='en', dest='zh-cn').text6 return text
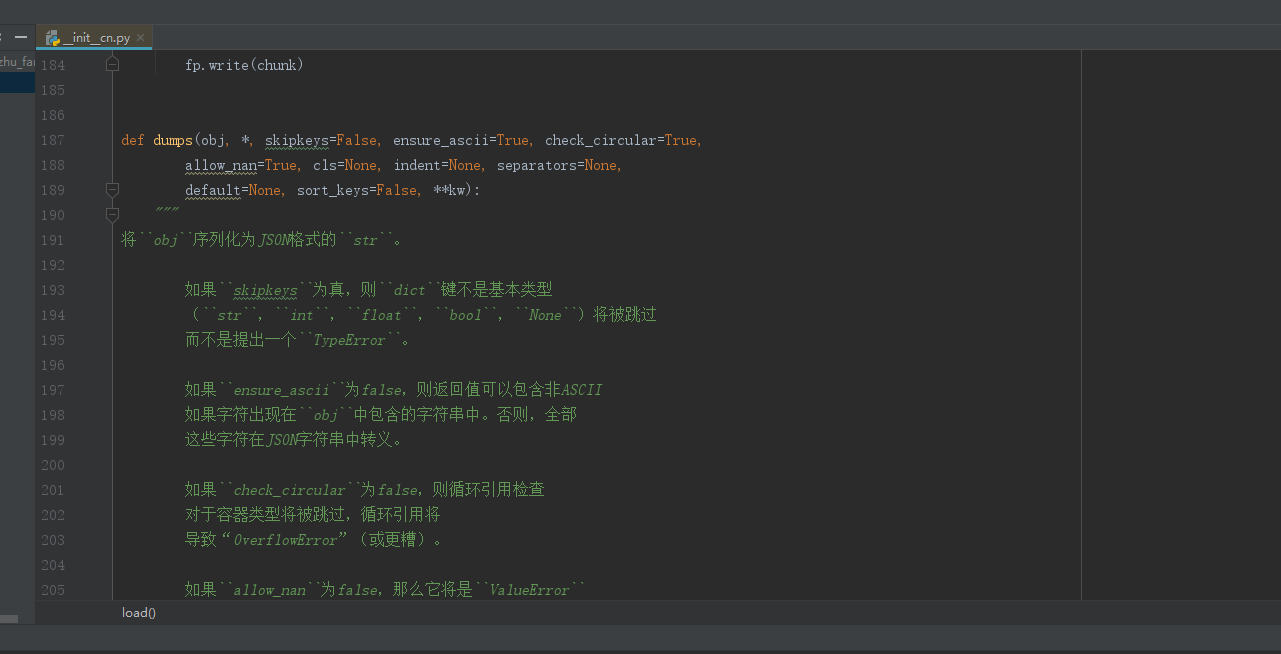
翻译后的结果图片如下: